CUDA Programming Applications
کاربردهای برنامه نویسی کوداCUDA Programming Applications
کاربردهای برنامه نویسی کودا
معیارهای ارزیابی
در تمامی عملیات بینایی ماشین و دیگر شاخه های هوش مصنوعی بدلیل آنکه انسان در برگرداندن خروجی هیچگونه مداخله ای ندارد، بایستی خروجی کار با پارامترهایی سنجیده شود تا نرخ خطا و دقت بازیابی مورد سنجش قرار گیرد و بدینوسیله عملکرد سیستم مورد ارزیابی قرار گیرد، از این رو 4 پارامتری که در تعیین دقت و خطای عملکرد نقش مهمی را ایفا می کنند در اینجا باختصار شرح داده شده است:
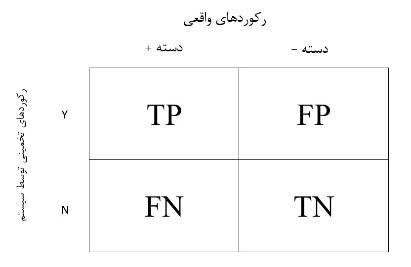
TN: این مقدار بیانگر تعداد رکوردهایی است که دسته واقعی آنها منفی بوده و الگوریتم دستهبندی نیز دسته واقعی آنها را بدرستی منفی تشخیص داده است.
FP: این مقدار بیانگر تعداد رکوردهایی است که دسته واقعی آنها منفی بوده و الگوریتم دستهبندی دسته آنها را به اشتباه مثبت تشخیص داده است.
FN: این مقدار بیانگر تعداد رکوردهایی است که دسته واقعی آنها مثبت بوده و الگوریتم دستهبندی دسته آنها را به اشتباه منفی تشخیص داده است.
TP: این مقدار بیانگر تعداد رکوردهایی است که دسته واقعی آنها مثبت بوده و الگوریتم دستهبندی دسته آنها را بدرستی مثبت تشخیص داده است.
شکل زیر نمونه ای از FN و FP را نشان می دهد.

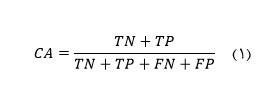
از این رو نرخ دقت بازیابی و همچنین نرخ خطا به ترتیب از روابط 1 و 2 محاسبه می شود:
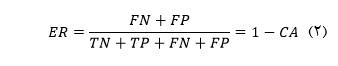
کتاب برنامه نویسی موازی با کودا

استفاده از توان محاسباتی رایانهها در تحقیقات علمی و
فعالیتهای دانشگاهی، مراکز تحقیقاتی و شرکتهای تجاری، کاربرد روزافزونی
پیدا نموده است؛ ازاینرو نیاز به پردازش سریعتر افزایش یافته و به یک
نیاز اساسی تبدیل شده است. سرعت کامپیوترهای شخصی کنونی نسبت به اجداد خود
بهطور سرسامآوری افزایش یافته است اما علیرغم وجود این موضوع باز جوابگوی
نیازهای مطرحشده نیست. ازجمله عرصههایی که احتیاج به کامپیوترهایی با
سرعت پردازش بسیار بالا دارند میتوان به برنامههای شبیهسازی در تحقیقات
هستهای، نانو فناوری محاسباتی، برنامههای پیشبینی وضعیت هوا، برنامههای
فیلمسازی کامپیوتری، برنامههای ساخت انیمیشن حرفهای و بسیاری از
زمینههای مختلف دیگر که همگی بهسرعت پردازش بسیار زیاد نیاز دارند تا در
یک زمان مناسب به نتیجه برسند اشاره کرد. یک راهحل برای این معضل، استفاده
از سوپرکامپیوترها است. درست است که سرعت پردازش سوپرکامپیوترها بسیار
بالاتر از کامپیوترهای شخصی است اما استفاده از آنها در همه موارد
مقرونبهصرفه نیست؛ ضمن آنکه این فناوری در انحصار بعضی از کشورهای
توسعهیافته است و سایر کشورها از دسترسی به این تجهیزات استراتژیک محروم
هستند. راهحل دیگر در دستیابی به سرعت پردازش بسیار بالا، استفاده از روش
پردازش موازی است. به بیان ساده در این روش چند پردازنده (در اینجا منظور
پردازندههای گرافیکی) معمولی با همکاری یکدیگر به اجرای یک برنامه
میپردازند که طی این همکاری، برنامه با سرعت بالاتری اجرا میشود. به
عبارت دیگر، پردازش یا محاسبهی موازی، شکلی از پردازش است که در آن
دستورالعملهای بسیاری در یک زمان و به صورت همزمان انجام میشوند و بر
اساس این اصل اجرا میشوند که مسائل بزرگ را اغلب میتوان به مسائل کوچکتر
تقسیم نمود که سپس باهم و بهصورت موازی اجرا شوند.
ادامه مطلب ...
Principal Component Analysis
تحلیل مولفه های اصلی(Principal Component Analysis)ابتدا در سال 1901 توسط پیرسون معرفی و پس از آن در سال 1933 توسط هتلینگ روشهای محاسباتی آن پیشنهاد شد،PCA در تعریف ریاضی یک تبدیل خطی متعامد است که داده را به دستگاه مختصات جدید برده بطوریکه بزرگترین واریانس داده ها بر روی اولین محور مختصات قرار گرفته و واریانس مرتبه بعدی بر روی دومین محور مختصات قرار می گیرد و این روند تا انتها ادامه می یابد.(شکل 1)
PCA یکی از با ارزشترین نتایج کاربرد جبر خطی است که به وفور در تحلیلهای مختلفی مانند شبکههای عصبی تا نمودارهای کامپیوتری استفاده شده است، چرا که یک روش آسان و ناپارامتری برای استخراج اطلاعات مرتبط از یک مجموعه داده پیچیده میباشد، بطوریکه کاربرد عمده روش PCA عبارتند از :
1- کاهش تعداد متغیرها
2- یافتن ساختار ارتباطی بین متغیرها که در حقیقت همان دسته بندی متغیرهاست
در زندگی روزمره زمانی که میخواهیم اشیا و یا اجسامی را باهم مقایسه کنیم بصورت ناخودآگاه شباهتهای آنها را کنار گذاشته و بیشتر به وجوه تمایز آنها دقت می نماییم.PCA استاندارد کاهش ابعاد را تنها از طریق پیدا کردن روابط خطی ممکن می سازد، اگر داده ها ساختارهای پیچیدهتری داشته باشند به نحوی که نتوان آنها را بخوبی در یک زیرفضای خطی نمایش داد PCA خطی نمیتواند مفید واقع شود. ادامه مطلب ...
کتابcomputer aided intelligent recognition techniques
در دو دهه اخیر کارهای با ارزشی در حوزه تشخیص کاراکتر صورت گرفته است و مقالات زیادی درباره این موضوع ارائه شده است، تشخیص کاراکتر تعامل خوبی را بین انسان و ماشین شامل پردازش اتوماتیک داده، اعتبارسنجی و غیره فراهم می نماید مانند برخی از نرم افزارهای بانکی (پرداخت قبض از روی بارکدو...)،نرم افزارهای علمی ، تجاری (مانند فروشگاههاو...)
مزیت دیگر نرم افزارهای تشخیص کاراکتر کاهش مداخله انسان در ورود داده و همچنین کاهش خطای تایپ تسریع امر خواندن داده می باشد، مخصوصا زمانی که داده به شکل خواندنی در سیستم موجود باشد، اما با تمام مزایایی که ذکر شد تشخیص حروف عربی بدلیل بهم پیوسته بودن حروف و شکل خاص حروف و سختی پردازش متن هنوز پتانسیل های زیادی را دارد،و همین پتانسل برای زبان چینی هم وجود دارد، کتاب computer aided intelligent recognition techniques در 24 فصل به معرفی و بررسی چندین الگوریتم و متد در مورد پردازش خودکار کاراکتر پرداخته است.
