CUDA Programming Applications
کاربردهای برنامه نویسی کوداCUDA Programming Applications
کاربردهای برنامه نویسی کودا
معرفی LBP و انواع آن
الگوی دودویی محلی در سال 1994 توسط Lowe Wang1ابداع گردید ، این الگو یک روش قدرتمند برای طبقه بندی بافتهای تصویر است که در سیستم بازیابی تصویر چهره کاربرد فراوان دارد و در روش معمولی الگوی باینری محلی از هیستوگرام برای استخراج ویژگی استفاده می نماید و از آنجایی که این روش هم از مشخصه های آماری و هم از ساختار بافتی استفاده می کند ابزاری قدرتمند برای تحلیل بافت به شمار می رود در این روش الگوهای دودویی محلی بوسیله مقایسه مقدار پیکسلهای مجاور با پیکسل مرکز الگوی بافت محلی استخراج می شود و با کدهای دودوئی نشان داده می شود ، این الگو در سال 1996 توسط اوجالا2و همکارانش پیشنهاد شد و به علت مقاومتش نسبت به تغییرات روشنایی و پیچیدگی محاسباتی کم و کدگذاری جزئیات یکی از رایج ترین توصیفگرهاست در اصل الگوی دودویی محلی برای آنالیز بافت پیشنهاد شده است و هنوز به عنوان یک رویکرد قدرتمند برای توصیف ساختار محلی معرفی می شود، و این الگو در بسیاری از کاربردهای گوناگون برای نمونه آنالیز تصویر چهره ،دریافت ویدیو تصویر ،مدلسازی محیط ،نظارت دیداری ،آنالیز حرکت ،آنالیز تصاویر هوایی و ... مطرح شده است.
انواع دیگر از توصیفگرهای الگوهای محلی دودویی در طول 5 سال اخیر پیشنهاد شدند و همچنین از چندین تحقیق صرفا برای الگوهای یکنواخت استفاده شد و با ترکیب الگوهای یکنواخت و غیر یکنواخت عملکرد الگوی محلی دودویی توسط ژو و همکارانش ارتقا داده شد .
انواع LBP
1-معمولی
2-دایره ای
3-قطری
که اصطلاحا آنها را به الگوهای خطی و محیطی تقسیم بندی می کنیم، در الگوهای محیطی مانند دایره ای چون ناحیه مدنظر نسبت به الگوی خطی مساحت بیشتری را دارد از درونیابی استفاده نموده و نقاط را با توجه به نقاط همسایه بازسازی می نماید در نتیجه کیفیت کار بالا می رود.

1- Lowe Wang

2- Timo Ojala
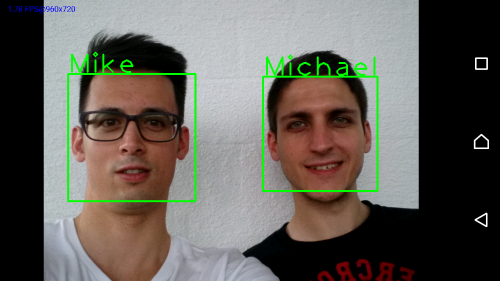
مفهوم Face Detection و Face Recognition
Face Detection
این ویژگی به دوربین کمک می کند تا چهره افراد را در تصویر به صورت خودکار شناسایی و روی آن زوم کند،این قابلیت موجب تنظیم فلاش و میزان نور ورودی است که از تار شدن و درخشندگی بیش از حد چهره افراد هنگام تصویر برداری جلوگیری می کند.


Face Recognition

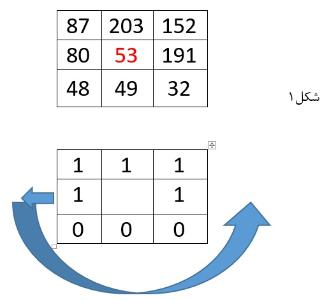
مفهوم LBP
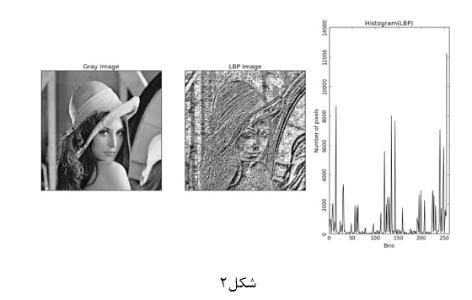
1) هیستوگرام:نمودار فراوانی هر رنگ در تصویر
در مرحله بعد فاصله هر یک از این بردارهای هیستوگرام را تا بردار هیستوگرام شکل مورد نظر را محاسبه می نماییم.
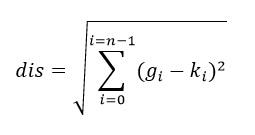
معماری کودا
اصطلاحات در کارتهای گرافیکی
Shaders ها برنامه های کوچکی هستند که میتوانند روی GPU اجرا شوند . این برنامه ها روی بلاک های GPU پخش می شوند و به صورت موازی اجرا می شوند . و در دو نوع Vertex و Pixcel وجود دارد . کارت های گرافیکی از واحدهای سایه زنی Vertex Shader و Pixel shader استفاده می کنند .
سایه زن راس : Vertex Shader : در پردازندهای گرافیکی واحدی وجود دارد که وظیفه ی ساخت پیکره بندی و اسکلت اجسام را برعهده دارد . این واحد سایه زن راس نام دارد . هر چه تعداد این واحدها بیشتر باشد . پردازنده یگرافیکی قدرتمندتر عمل میکند . در کارت های گرافیک جدید . سایه زن جای خود را به پردازندهای جریانی واگذار کرده است که به انها SM یا Streaming Multiprocessor گفته میشود . این برنامه بیشتر در autocad,corel استفاده می شود .
سایه زن پیکسل PIXCEL SHADER : : پردازندهای گرافیکی برای ان که بتواند به اجسام ساخته شده توسط سایه زن روح ببخشد و ان ها را در دنیای واقعی نزدیکتر کنند به واحدی به اسم سایه زن پیکسل نیاز دارند . در حقیقت سایه زن پیکسل رنگ و میزان نور هر یک از پیکسل های اجسام ساخته شده توسط سایه زن راس را تعیین میکند . این سایه زن موجب ایجاد اثرات . سایه ها .روشنایی .ماتی ودیگر پدیده های یک تصویر می شود .به دلیل نقش مهمی که این سایه زن در یک پردازنده گرافیکی دارد. عموما تعداد انها نسبت به تعداد سایه زن راس بیشتر است . به عنوان مثال کارت گرافیک GeForce 7800GTX دارای 48 عدد سایه زن پیکسل و هشت پردازنده ی راس می باشد.
پردازنده ی جریانی : Stream Multiprocessor : پردازنده های گرافیکی مبتنی بر Directx نسخه ی 10 شامل تغییرات عمده ای در معماری شدند .در این پردازنده های گرافیکی سایه زن و پیکسل حذف شدند و پردازنده جریانی جایگزین انها شدند . هر پردازنده جریانی تقریبا مشابه با یک پردازنده ی بسیار کوچک است و به تنهایی وظایف مربوط به سایه زن های راس و پیکسل را انجام می دهد .پردازنده های گرافیکی شرکت NVIDIA از سری 8000 به بعد و شرکت ATI از 2000 به بعد دارای این پردازنده های جریانی هستند . به عنوان مثلا پردازنده ی گرافیکی شرکت انویدیا با نام GEFORCE GTX 285 دارای 240 پردازنده ی جریانی هست که هر یک به تنهایی می تواند وظایف سایه زنی راس و پیکسل را انجام دهد.)شکل شماره 10(

8- برنامه نویس ناهمگن
برنامه نویسی ناهمگن گونه ای از برنامه نویسی است که در ان قست های مختلف کد تولید شده . برروی گونه های مختلفی از پردازنده اجرا میشود . به عنوان مثال می توان کدی را تصور کرد که برخی از قسمت های ان بر روی CPU و برخی از اجزای دیگر ان بر روی پردازنده های کارت گرافیکی اجرا می شوند . این مفهوم می تواند کمک شایانی به بهره بری بیشتر از توان محاسباتی رایانه ها کند. چرا که می توان از همه ی ظرفیت ها پردازشی یک سامانه به طور همزمان استفاده کرد .بدیهی است که برای استفاده حداکثری از این ظرفیت باید چار چوب فراهم شودکه توسعه چنین کدهایی را تسهیل نماید . معماری CUDA چار چوبی مناسب برای توسعه ی برنامه ی ناهمگن است . این معماری بستری را فراهم می کند که به کمک ان می توان کدهایی ایجاد کرد که قطعه های مختلف ان توانایی اجرا شدن بر روی پردازنده های کارت های گرافیکی و یا پردازنده های اصلی رایانه را دارند . در این معماری دو سکوی اجرایی با نام های host platform device platform درنظر گرفته شده است . سکوی host شامل یک یا چند پردازنده ی معمولی یا چند هسته ای د رکارت های گرافیکی NVIDIA است و قطعه ی کد مربوط به ان در نخ های اجرایی بسیار سبک و به صورت موازی اجرا می شوند شکل 11 این دو سکوی اجرایی را نشان می دهد

کدی که بر روی سکوی HOST اجرا می شوند یک کد عادی است و با زبان های معمول برنامه نویسی مانند C نوشته و کامپایل می شوند .اما کد دستوری device به علت ساختار اجرایی متفاوتش APIها و نیز دستورات سطح بالای خاصی دارد بنابراین باید با کامپایلری مناسب و متفاوت از کامپایلرهای عادی کامپایل شود . انم این کامپایلر nvcc است که به همراه تمامی ان چیزی که برای توسعه کد های device مورد نیاز است در یک بسته به نام CUDA Toolkit گرد اوری شده است

شکل13:اجرای برنامه ها توسط پردازنده های مختلف در قالب یک برنامه
9- محاسبات ناهمگن در پردازنده گرافیکی
در یک دسته بندی کلی . محاسباتی را که در یک رایانه انجام می شود می توان به دو دسته موازی (همزمانی ) و سریال (همگامی ) تقسیم کرد . منظور از محاسبات موازی محاسباتی است که از یکدیگر مستقل بوده و امکان انجام انها به صورت همزمان وجود دارد . محاسبات سری بر خلاف محاسبات موازی به یکدیگر وابسته بوده و باید به ترتیب و یکی پس از دیگری انجام شوند . پردازنده مرکزی به لحاظ دارا بودن برخی از خصوصیات فنی از نظیر حافظه کش و انشعابهای زیاد توانایی بالایی برای انجام محاسبات سری را دارد . برعکس پردازنده گرافیکی به دلیل توانایی هایی بالایی که در انجام محاسبات شناور دارد برای محاسبات موازی بسیار ممکن است و می تواند انها را بسیار سریعتر انجام دهد . بتابراین به نظر میرسد که برای رسیدن به بالاترین راندمان باید از پردازنده مرکزی در محاسبات سری واز پردازنده گرافیکی در محاسبات موازی استفاد کرد . محاسبات ناهمگن همین انتخاب درست پردازنده برای هر نوع از محاسبات و عملکردها می باشد .مدل محاسبات پردازنده گرافیکی استفاده از یک CPUو یک GPU به همراه یکدیگر در یک مد پردازشی ناهمگن است . قسمت ترتیبی کاربرد روی CPU وقسمت سنگین محاسبات روی GPU اجرا می شود . از دیدگاه کاربر کاربد ها سریعتر اجرا می شوند زیرا ازکارایی بالای GPU و موازی سازی در افزایش کارایی استفاده شده است .CPU و GPU فضا های حافظه های مجزایی دارند و هیچ دسترسی مستقیمی به حافظه GPU وجود ندارد. برای اینکه کاربردها بتوانند از حافظه GPU استفاده کنند باید داده ها ابتدا در حافظه GPU ذخیره شوند . کد میزبان (CPU) انتقال داده به حافظه دستگاه (GPU ) را مدیریت می کند و سپس محاسبات موازی روی GPU انجام میشود . کد میزبان مسئول تخصیص و باز پس گیری حافظه از GPU است یکی از مدهای عملیاتی GPU یه صورت شکل زیر است .( شکل شماره 14)

1-داده از حافظه اصلی CPU به حافظه GPU کپی میشود
2- CPU دستور العمل های پردازشی را برای GPU ارسال می دهند
3- هسته های GPU دستور العمل هایی را به صورت موازی انجام می دهند .
4- نتیجه از حافظه GPU به حافظه اصلی کپی می شود .
10- معماری داخلی هسته کودایی یک کارت گرافیک
GPU های Fermi حداکثر دارای 512 هسته کودایی هستند که هر هسته کودایی در هر کلاک یک دستور العمل اعشاری با دقت تکی یا یک دستور العمل صحیح را به ازای هر thread اجرا می کند . فرکانس کاری فرمی حدود 1.5 گیگا هرتز می باشد . یعنی می توان 1.5 میلیارد عملیات ممیز شناور را در هر ثانیه انجام داد . این 512 هسته کودایی به 16 گروه تقسیم می شوند که به هر گروه یک(Streaming Processor) SM گفته میشود .بنابراین هر SM دارای 32 هسته کودا خواهد بود که به ان پردازنده کودا نیز گفته میشود . در شکل 15 SM ها در صورت مستطیل های سبز رنگ نمایش داده شده اند و هر کدام شامل 32 هسته هستند . داخل هر بسته کودا یک ALU صحیح و یک ALU واحد ممیز شناور قرار دارد هر کدام از این 16 عد SM یک کش L2 با ظرفیت 768 کیلو بایت احاطه می کند. هر SM دادای بخش های کش . رجیستر Warp Dispatch می باشد که دو بخش انتهایی وظیفه اماده شدن برای پردازش بعدی را به عهده دارد.

شکل شماره 15:ساختار داخلی هسته کودایی کارت گرافیک شرکت NVIDIA با معماری فرمی
داخل هر SM دارای 4 ستون است که شامل 32 هسته کودا،16واحد لود و ذخیره (LD /SD) 4 واحد توابع خاص SFU می شود واحد لود و ذخیره ادرس های مبدا و مقصد را برای 16 Thread در هر کلاک محاسبه می کند . واحد SFU انواع خاصی از دستور العمل ها را مثل کسینوس و جذر را محاسبه می کند . هر SUF نیز می تواند یک دستور العمل را در هر کلاک اجرا کند.حداکثر 32Thread موازی در هر SM زمان بندی می شوند تا اجرا شوند که به این کار WARP گویند. این زمان بندی در واحدی به همین نام یعنی WARP انجام می شود .هرSM دارای 2 واحد زمانبندیWARPو دو واحدDispatch است و این پیکربندی می تواند دو Warp را همزمان اجرا کند GPU های فرمی داری 6 کنترلر حافظه 64 بیتی هستند که در شکل 15 به صورت DRAM نشان داده شده است .این کنترلرها، دادها را به هسته های CUDA تحویل می دهند

شکل شماره 16:معماری داخلی یک SM
11- نحوه انجام محاسبات در GPU
عمدتا محاسبات مربوط به کاربردهای گرافیکی شامل محاسبات ریاضی ماتریسی است زیرا در هر لحظه نیاز به پردازش ماتریس پیکسل های تصویر داریم . بدیهی است که با افزایش میزان تفکیک پذیری تصاویر حجم این ماتریس ها بزرگ می شود و اگر بخواهیم کل محاسبات ماتریسی خود را به تنهایی و توسط پردازنده های اصلی سیستم انجام دهیم امکان ناتوانی پردازنده درپاسخ به نیازهای برنامه های گرافیکی وجود خواهد داشت . لذا برای غلبه براین مشکل کارت های گرافیکی پای به عرصه وجود گذاشتند . هرکارت گرافیکی حاوی تعداد نسبتا زیادی ریز پردازنده است که به صورت موازی کار می کنند و هر کدام از ان قسمتی از ماتریس تصویر را پردازش می کند . به عبارت بهتر در پردازش یک تصویر خاص کل ماتریس ان تصویر به تعدادی زیر ماتریس کوچکتر تقسیم شده و محاسبات انها به صورت موازی ودر نخ های پردازشی بسیار سبک صورت میگیرد . مثلا به جای اینکه محاسبات مربوط به یک ماتریس 400*400 را به پردازنده ی اصلی واگذار کنیم میتوان این ماتریس را به 1600 زیر ماتریس کوچک 10*10 تقسیم کرد و هر کدام از این ماتریس های کوچک را در یک نخ اجرایی سبک و برروی ریز پردازندهای کارت گرافیکی به صورت موازی اجرا کرد .
پردازنده های گرافیکی، پردازنده های چند هسته ی بسیار موازی هستند و در گروه کامپیوترهای موازی یک دستور العمل چند داده SIMD قرار دارند . در پردازنده های گرافیکی یک عملیات یکسان به طور همزمان روی چند داده اجرا می شود . درحال حاضر میان افزار کودا . پرکاربردترین ابزار برنامه نویسی بر پایه پردازنده گرافیکی است . کودا یک مدل برنامه نویس موازی ++C/C است واز مدل برنامه نویسی سریال – موازی ناهمگن پیروی میکند . کودا به CPU های چند هسته ای نیز به خوبی نگاشت میشود . کودا مجموعه های از کرنل ها و یا توابع کامپایلر nvcc کتابخانه های پیشتیبان و درایورهای سخت افزاری را ارائه میدهد .فناوری کودا سرعت عملکرد پردازش گرافیکی را از طریق تحت کنترل در اوردن قدرت GPU امکانپذیر میکند. این فناوری اجازه میدهد صدها تراشه گرافیکی مجزای انویدیا در کنار هم به پردازش موازی اطلاعات بپردازد . مدل برنامه نویسی کودا . کاملا روی موازی سازی داده تمرکز دارد . کودا با ارائه انتزاع های برنامه نویسی سبک وزن و مناسب . به برنامه نویسان اجازه میدهد تا کرنلها را با استفاده از نخ ها اجراء کنند .در زمان اجراء این نخ ها . به مجموعه ای از بلوک ها که شامل دهها نخ هستند و به طور همروند با هم کرده و منابع را به اشتراک میگذارند .بسط داده می شوند هر چند کودا به دنبال انتزاعی کردن جزئیات سخت افزار است اما اگاهی از معماری سخت افزار مورد استفاده هنوز هم برای برنامه نویسانی که کارایی برایشان اهمیت زیادی دارد مهم است . برای ایجاد پیاده سازیهای کار امد روی پردازنده گرافیکی به درک کامل معماری مورد استفاده . مدل نخ و مدل حافظه نیاز است .
12- کرنل ، نخ و روند اجرایی انها در GPU
کرنل . یک تابع مانند توابع نرمال زبان C است که روی ماشین میزبان یا همان CPU فراخوانی شده و روی ماشین دستگاه یا همان GPU اجرا می شود . در فراخوانی یک کرنل . نخ های زیادی اجرا شده و امکان محاسبات موازی را فراهم می نمایند . نخها در GPU به صورت همزمان یک دستور یکسان را روی داده های متفاوت اجراء می کنند . یک کرنل در کودا توسط ارایه ای از نخ ها اجرا میشود . به تعداد نخ های تعیین شده در کرنل از تابع کپی گرفته شده و به هر نخ یک کپی از تابع داده میشود تا بتواند دستور را روی داده ی خود اجرا نماید . در طول اجرای یک کرنل .همه نخ ها کد یکسانی را اجرا می کنند .هر نخ . دارای شناسه (ID) است که از ان برای محاسبه ادرسهای حافظه و تصمیمات کنترلی استفاده می شود . می توان گفت که نخ ، اجرایی از یک کرنل با یک شناسه یا شاخص خاص است هر نخ ، از شاخص خود برای دسترسی به عناصری که در یک مجموعه هستند . استفاده می کتد .مهمترین ویژگی های نخ های کودا عبارتند از :
1- نخ های بی اندازه سبک وزن هستند
2- سربار ایجاد انها بسیار کم است
3- از سوئیچ کردن فوری پشتیبانی می کنند.
روند اجرای نخ در سخت افزار پردازنده گرافیکی طی مراحل زیر انجام می شود :
1- فراخونی کرنل با دستوری مشابه با KernelFunction////dimGrid. dimBlock //// انجام میشود . سپس بلوک های نخ به صورت سریالی بین همهSM هایی که بطور بالقوه دارای بیش از یک بلوک نخ در هر SM هسنتد، توزیع می شوند .
2- بلوک های نخ متلق به هر SM به صورت تارهایی warp از نخ هاپس از فراخوانی کرنل توسط سخت افزار اغاز به کار میکند SM تارهایی که اماده اجرا روی چند پردازنده هایی جریانی هستند را زمان بندی و اجرا می کند .
3- محاسبات موازی توسط نخ ها در GPU انجام می شود
4- کرنل پس از تکمیل محاسبات موازی به اتمام رسیده و تمام منابع ازاد میشود
سازمان دهی نخ های کودا در بلاک و گرید
بلوک یا بلاک .گروهی از نخ ها است (شکل 17) هماهنگی نخها با استفاده از تابع syncthreads انجام می شوند این تابع باعث توقف یک نخ در یک نقطه خاص در کرنل می شود تا زماینکه نخ های دیگر درون بلوک به همان نقطه برسند . تار warp یک گروه متشکل از 32 نخ است که به صورت SIMD توسط SM اجرا میشوند . تارها واحدهای زمان بندی در یک SM هستند . هر بلوک نخ به تارهای 32 نخی مستقیم می شود و نخ های درون تارها روی پردازندهای اسکالر اجراء می دشوند . برای مثال اگر 3 بلوک به یک SM اختصاص داده شود و هر بلوک دارای 256 نخ باشد . تعداد تارها در هر بلوک برابر 8 (32/256) خواهد بود . این موضوع نشان میدهد که برای 3 بلوک 24 تار داریم . در هر لحظه تنهایی یکی از 24 تار برای واکشی و اجرای دستور العمل می شوند . زمانبندی تارها به صورت زیر انجام میگردد.
1-سخت افزار SM زمابندی تار با سربار صفر را پیاده سازی میکند
2-تارهایی که عملوندهای دستور العمل بعدی را دراختیار دارند دارای اولویت برای اجرا هستند .
3-تارهای واجد شرایط براساس یک سیاست زمانبندی برای اجرا انتخاب میشود
4-همه ی نخ های درون یک تار در صورت انتخاب شدن .دستور العمل یکسانی را اجرا می کنند.
گروهی از بلوکها یک گرید را شکل می دهند . در کودا . کرنل یک گرید از بلوکهای نخ را اغاز می کند . این بلوک های نخ روی SM ها اجرا می شوند . نخ های درون هر بلوک روی پردازندهای اسکالر اجرا شده و میتوانند از طریق حافظه مشترک با هم همکاری کنند. نخ های درون بلوک های مختلف نمی تواند با هم همکاری داشته باشند .

شکل شماره 17:سلسله مراتب دو بعدی از بلوکها و نخها در پردازش یک تصویر 48*32 پیکسلی با استفاده از یک نخ در هر پیکسل

شکل 17و18 رابطه میان مولفه های مختلف کودا را نشان می دهد . می توان دید که معماری گرافیکی برای موازی سازی است . GPU پردازشگری است که به دلیل استفاده از معماری موازی و استفاده از تعداد هسته های زیاد امکان پردازش کاراتری را نسبت به CPU فراهم می کند ودر عین حال هزینه پایینی دارد . همچنین کودا .امکان استفاده از این معماری را به کاربر می دهد .

شکل 19: سلسه مراتب سازمان دهی نخ های اجرایی در کودا
برای دسترسی به یک نخ خاص متغیرهای درونی ویژه ای وجود دارد که در زبانهای برنامه نویسی حامی CUDA تعبیه شده اند . همچنین متغیرهای درونی ویزه ای نیز برای پی بردن به ابعاد تور و بلوک های ایجاد شده در نظر گرفته شده است . این متغییرها نیز عمدتا سه بعدی هستند .

در معماری CUDA حافظه ی کارت گرافیکی به خاطر افزایش کارایی دارای سلسه مراتب به شرح زیر است
1* st place : Register file
2*nd place : Shared Momory
3*rd place :Constant Memory
4*th : Texture Memory
*Tie for last place : Local Memory and Global Momory
Register ها : به ازای هر نخ یک register وجود دارد که طول عمر داده های درون ان نیز به اندازه ی عمر نخ خواهد بود

شکل 21:حافظه Register و نخ
Shared memory به ازای هر بلوک از نخ ها یک قسمت حافظه ی مشترک وجود دارد که موجبات همکاری نخ های آان بلوک را فراهم می سازد . عمر داده های درون ان به اندازه عمر بلوک متناظر ان است و در ضمن زمان دسترسی به ان نیز کم است و لذا داده هایی که در ان قرار میگیرد در زمان سریعتری قالب دسترس اند

Local momory به ازای هر نخ در قسمت DRAM کارت گرافیکی یک قسمت حافظه ی محلی وجود دارد که عمر داده های درون ان به اندازه ی عمر نخ است

Global (device) memory این حافظه یک حافظه عمومی است که هم توسط CPU و هم توسط تمامی نخ ها قابل دسترسی است . طول عمر داده ها درون ان هم از زمان Allocation تا زمان De allocation است .ویژگی های این حافظه زمان تاخیر زیاد . ظرفیت بالا و عدم cache شدن است

شکل24:حافظه Device
Host(CPU) memory این حافظه به صورت مستقیم در دسترس نخ های device نیست . بنابراین برای اینکه device بتواند پردازشی روی ان ها انجام دهد باید داده ها درون ان ابتدا از حافظه های device انتقال یابد .
به ازای هر نخ یک حافظه local memory ویک رجیستر وجو دارد و در سطح بعد . برای بلوک حافظه یک Shared momory ودر نهایت به ازای هر device یک حافظه ی global داریم . برای افزایش کارایی برنامه های CUDA سلسه مراتبی شامل تور. بلوک .و نخ در نظر گرفته شده است . حال زمان ان رسیده است تا بدانیم که اجرای این واحدها بر روی سخت افزار ها به چه صورت است . در شکل 25 با یک نمای ساده از ارتباطات سخت افزاری CUDA اورده شده است .

در شکل 25 Global memory حافظه عمومی device است و SMEM خلاصه شده ی عبارت Shared memory است . هر بلوک از تور بر روی یک multiprocessor اجرا می شود " البته این امکان وجود دارد که چند بلوک روی یک multiprocessor اجرا شوند که این امر وابسته به منابع موجود در هر multiprocessor ونیز به ابعاد بلوک ها ست و درضمن اجرای یک نخ از یک multiprocessor وبه یک multiprocessor دیگر انتقال نخواهد یافت .

شکل26:سیستم معماری در موازی سازی CUDA


شکل 28 : حافظه اشتراکی در کودا
نخ های هر بلوک بسیار سبک اند و نیز به سادگی از حالت اجرا به حالت انتظار می روند و بلعکس . در واقع ایده ی اصلی برای این کاردر معماری CUDA این است که برای تعویض حالت اجرای یک نخ نیازی به ذخیره سازی اطلاعات PCB نیست . PCB بلوکی است که سیستم عامل اطلاعات هر پردازش رادر ان ذخیره می کند تا وضیعت اجرایی Process حفظ شود .پس از انکه مجددا نوبت اجرا به این پردازش رسید . اطلاعات PCB ان وضعیت رجیسترها و ..را بازیابی کنند . هر multiprocessor به تعداد حداکثر نخ های که میتواند اجرا کند register دارد که یک محدودیت سخت افزاری است . مثلا فرض کنید که یک multiprocessor حداکثر توانایی اجرای 256 نخ را داشته باشد . دراینصورت 256 رجیستر نیز خواهد داشت . درهر لحظه یکی از این نخ ها اجرا می شود و سپس اجرای ان رها شده ونوبت به دیگری می رسد . منتها برای تعویض اجرا نیازی به ذخیره سازی حالت نخ در حال اجرا نیست . زیرا تعداد کافی رجیستر در اختیار داریم .پس باخیال راحت اجرای ان را رها کرده و به سراغ نخ بعدی می رویم . نکته دیگری که دررابطه وجود دارد این است که تعداد بلوک هایی که می توانند به صورت همزمان روی یک multiprocessor اجرا شوند. بستگی به میزان منابع multiprocessor و نیز ابعاد بلوک دارد . قسمت shared memory در شکل 28 حاظه ی مربوط بین نخ های یک بلوک است که برای همکاری این نخ ها تعبیه شده است Global memory نیز حافظه ای از DRAM مربوط به device است که پل ارتباطی host و device به شمار میرود . مدیریت اجرا و شناسه دهی به نخ هایی که multiprocessorها اجرا میکنند با خود انهاست . واحدهای زمانبندی در multiprocessor ها wrap نام دارند . هر wrap شامل تعداد نخ است . درهر زمان واحد زمانبند یک wrap را به حالت اجرا می برد . multiprocessor روی تمامی نخ هایwrapمذکور دستور واحدی را اجرا می کند . به عنوان مثال اگر فرض کنیم که مثال قبلی هر 32 wrap نخ را در خود جای میدهد . انگاه هر بلوک ما 4=32/128wrap خواهد داشت و multiprocessor در کل 2/4 یعنی 8 wrap خواهد داشت. با گذر زمان هر بار . multiprocessor یک wrap را برداشته و دستور مناسب را درمورد ان اجرا کرده و به سراغ wrap بعدی می رود .
13-همکاری نخ ها
برای افزایش کار امدی کد در CUDA . این امکان فراهم شده است که نخ ها بتوانند با یکدیگر همکاری داشته باشند . این همکاری می تواند در زمینه ی دسترسی به حافظه باشد که باعث کاهش پهنای باند مصرف شده در برنامه می شود و یا میتواند در زمینه ی اشتراک نتایج بدست امده باشد که در این حالت سربار محاسبه ی مجدد برای هر نخ کاهش می یابد .لازم به ذکر است که همکاری بین تمام نخها قابل پیاده سازی نیست . زیرا اگر تعداد نخ های برنامه زیاد باشد نه تنها کارایی را افزایش نمدهد بلکه سبب کاهش ان نیز خواهد شد . بنابراین همکاری نخ ها فقط در یک بلوک صورت میگیرد . در حقیقت دسته بندی نخ ها در قالب بلوک های مجزا در یک تور به همین منظور صورت گرفته است . در هر بلوک یک حافظه shared memory وجود دارد که بین نخ های ان بلوک مشترک است و نخ های ان بلوک می توانند از داده های درون ان استفاده کرده یا نتایج محاسبات خود را در ان قراردهند . علاوه بر همکاری از طریق حافظه ی مشترک نخ های درون یک بلوک می توانند اجرایشان رانیز با هم synchronize کنند.
تـــذکر : نخ های یک بلوک نمیتواند با نخ های بلوک های دیگر همکاری داشته باشند . مدیریت حافظه هر کدام از device ها و host حافظه مربوط به خود را دارند . مدیریت حافظه device در کد host صورت می گیرد . این مدیریت شامل گرفتن و پس دادن حافظه . کپی کردن به device یا برداشتن اطلاعات از ان است .
Memory Allocation and Release
به کمک توابع زیر میتوان حافظه ای به اندازه مورد نیاز در قسمت device از global memory گرفت یا ان را پس داد.
. cuda Malloc(void**Pointer . size _ t nbytes )
. cuda Memset (void**Pointer .int value . size _ t nbytes )
. cudaFree (void**Pointer)
توابع cudaMalloc و cudaFree به ترتیب حافظه ی مورد نیاز را می گیرند و پس می دهند cudaMemset هم داده ی مورد نظر را در حافظه ی گرفته شده قرار می دهد . به کمک تابع زیر می توان فضایی از حافظه host یا device را در فضایی از حافظه ی host یا device قرار دهد .
CudaMemcpy ( void *dest . void * source . size _t bytes . enum cudaMemcpyKind direction )
enum cudaMemcpyKind میتواند یکی از مقادیر زیر را بگیرد .
· Cuda Memcpy Host Device
· Cuda Memcpy Device To Host
· Cuda Memcpy Device Device
· Host synchronization
· همه اجراهای kernel به صورت غیر همگام صورت میگیرد . بدین معنا که بلافاصله پس ا زاجرا و پیش از اینکه اجرای همه نخ ها به پایان برسد به CPU باز می گردد . برای همگام کردن نخ های د رحال اجرا از تابع cudaThread synchronize استفاده می شود . همچنین لازم به ذکر است که تابع CudaMemcpy به صورت همگام اجرا می شود . بدین معنا کپی اغاز نمی شود تا همه ی فراخوانی های قبلی CUDA کامل شود و نیز کنترل به CUP باز نمی گردد تا اینکه کل عملیات کپی کردن صورت گیرد .